
原文来源:机器之心

图片来源:由无界 AI生成
迄今为止规模最大,能力最强的谷歌大模型来了。
当地时间 12 月 6 日,谷歌 CEO 桑达尔・皮查伊官宣 Gemini 1.0 版正式上线。
这次发布的 Gemini 大模型是原生多模态大模型,是谷歌大模型新时代的第一步,它包括三种量级:能力最强的 Gemini Ultra,适用于多任务的 Gemini Pro 以及适用于特定任务和端侧的 Gemini Nano。

现在,谷歌的类 ChatGPT 应用 Bard 已经升级到了 Gemini Pro 版本,实现了更为高级的推理、规划、理解等能力,同时继续保持免费。谷歌预计在明年初将推出「Bard Advanced」,其将使用 Gemini Ultra。
这是 Bard 问世以来最大的更新。
自 ChatGPT 发布以来,我们一直对谷歌声称的竞品 Gemini 模型的能力非常好奇,这款大模型早在今年 3 月就有了风声,5 月的 I/O 大会上进入「即将推出」的状态。
随着知情人士不断透露新信息,我们能了解到:据说 Gemini 有万亿参数,训练动用的算力是 GPT-4 的五倍。但 Gemini 的正式发布却似乎因为各种原因而屡遭推迟。
为了与 OpenAI 和微软展开竞争,谷歌果断从 PaLM 2 切换到了 Gemini 上,甚至在今年 4 月份直接把谷歌大脑(Google Brain)和 DeepMind 合并在了一起,Gemini 就由新组成的 Google DeepMind 汇合两个实验室的力量进行攻关。

可见谷歌在大模型军备竞赛上孤注一掷的心态。
那么,Gemini 真的能够给我们带来惊喜吗?除了在各种 Benchmark 上拿到最优成绩,甚至超越人类以外,有趣的是,在新闻发布会上,面对记者有关「Gemini 相比以前的大模型有哪些新能力」的提问,Google DeepMind 产品副总裁 Eli Collins 回答说:「我怀疑有」,表示谷歌仍然在努力了解 Gemini Ultra 的全部能力。
以下为谷歌 CEO 皮查伊的声明:
每一次技术变革都是推进科学发现、加速人类进步和改善生活的机会。我相信我们现在所看到的人工智能转变将是我们一生中最深刻的转变,远远大于之前向移动或网络的转变。人工智能有潜力为世界各地的人们创造从日常生活到非凡的机会。它将带来新一波的创新和经济进步,并以前所未有的规模推动知识、学习、创造力和生产力。这让我感到兴奋:有机会让人工智能为世界各地的每个人提供帮助。作为一家人工智能优先的公司,我们已经走过了近八年的历程,进步的步伐只会不断加快:数百万人现在在我们的产品中使用生成式人工智能来完成一年前无法完成的事情,从寻找答案到更复杂的问题使用新工具进行协作和创造的问题。与此同时,开发人员正在使用我们的模型和基础设施来构建新的生成式人工智能应用程序,世界各地的初创公司和企业正在利用我们的人工智能工具不断成长。这是令人难以置信的势头,然而,我们才刚刚开始触及可能性的表面。我们正在大胆而负责任地开展这项工作。这意味着我们的研究要雄心勃勃,追求能够为人类和社会带来巨大利益的能力,同时建立保障措施并与政府和专家合作,应对人工智能变得更加强大的风险。我们将继续投资最好的工具、基础模型和基础设施,并在我们的人工智能原则的指导下将它们引入我们的产品和其他产品中。谷歌大模型 Gemini 正式发布
谷歌 DeepMind CEO 和联合创始人 Demis Hassabis 代表 Gemini 团队正式推出了大模型 Gemini。
Hassabis 表示长久以来,谷歌一直想要建立新一代的 AI 大模型。在他看来,AI 带给人们的不再只是智能软件,而是更有用、更直观的专家助手或助理。
今天,谷歌大模型 Gemini 终于亮相了,成为其有史以来打造的最强大、最通用的模型。Gemini 是谷歌各个团队大规模合作的成果,包括谷歌研究院的研究者。
特别值得关注的是,Gemini 是一个多模态大模型,意味着它可以泛化并无缝地理解、操作和组合不同类型的信息,包括文本、代码、音频、图像和视频。
谷歌表示,Gemini 还是他们迄今为止最灵活的模型,能够高效地运行在数据中心和移动设备等多类型平台上。Gemini 提供的 SOTA 能力将显著增强开发人员和企业客户构建和扩展 AI 的方式。

目前,Gemini 1.0 提供了三个不同的尺寸版本,分别如下:
- Gemini Ultra:规模最大、能力最强,用于处理高度复杂的任务;
- Gemini Pro:在各种任务上扩展的最佳模型;
- Gemini Nano:用于端侧(on-device)任务的最高效模型。
谷歌对 Gemini 模型进行了严格的测试,并评估了它们在各种任务中的表现。从自然图像、音频和视频理解,到数学推理等任务,Gemini Ultra 在大型语言模型研发被广泛使用的 32 个学术基准测试集中,在其中 30 个测试集的性能超过当前 SOTA 结果。
另外,Gemini Ultra 在 MMLU(大规模多任务语言理解数据集)中的得分率高达 90.0%,首次超越了人类专家。MMLU 数据集包含数学、物理、历史、法律、医学和伦理等 57 个科目,用于测试大模型的知识储备和解决问题能力。
针对 MMLU 测试集的新方法使得 Gemini 能够在回答难题之前利用其推理能力进行更仔细的思考,相比仅仅根据问题的第一印象作答,Gemini 的表现有显著改进。
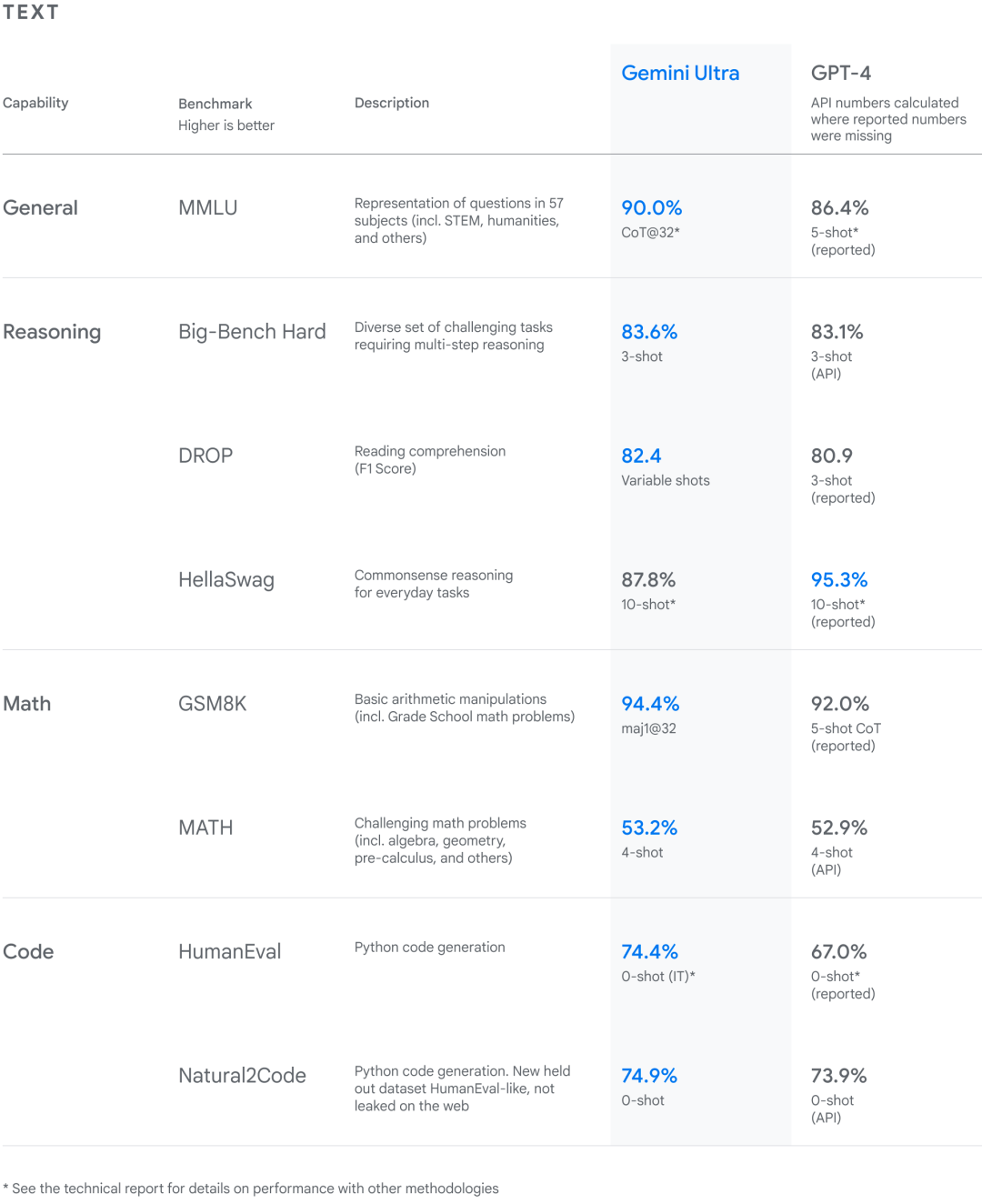
在大多数基准测试中,Gemini 的性能都超越了 GPT-4。
更多细节,请查看详细的测试报告:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
在最新版本的 MMMU 测试集中,Gemini Ultra 也取得了得分为 59.4% 的最佳成绩。增强版的测试集由需要慎重推理的多模态任务组成。
在图像基准方面的测试中,Gemini Ultra 不需要从图像中提取文本就能进行 OCR 处理,这凸显了 Gemin 内置的强大多模态能力,也初步显示了 Gemini 具有更复杂推理能力的先兆。
下一代全方位能力升级
Gemini 在设计时原生地支持多模态,从一开始便在不同模态上进行了预训练,然后利用额外的多模态数据进行微调以提升有效性。因此,Gemini 能够无缝地理解和推理各种输入,远远优于现有多模态模型,并且它的能力在几乎每个领域都是最强的。
复杂推理能力
Gemini 1.0 具有复杂多模态推理能力,可以帮助理解复杂的书面和视觉信息。这使得它尤其擅长发现海量数据中难以辨别的知识。Gemini 1.0 通过阅读、过滤和理解信息具有了从数十万份文件中提取 insights 的超凡能力,这有助于科学、金融等诸多领域以超快的速度取得新突破。
同时理解文字、图像、音频以及更多模态的信息
经过训练,Gemini 1.0 可以同时识别和理解文本、图像、音频等,因此它能够更全面地理解输入中信息的细节,也能回答与复杂主题相关的问题。因此,它特别擅长对数学和物理等复杂学科的问题进行推理。
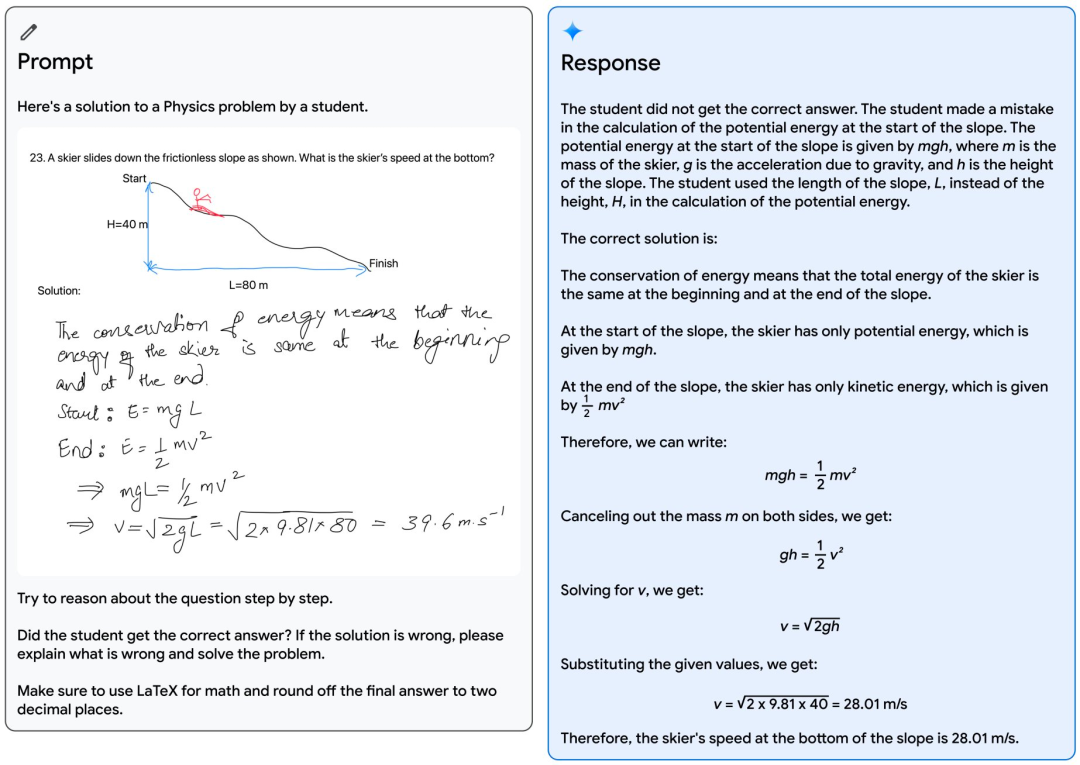
如下图所示,一位老师画了一个滑雪者从斜坡上下来的物理问题,而一位学生则提出了一个解决方案来计算滑雪者在斜坡底部的速度。利用Gemini的多模态推理能力,该模型能够读懂凌乱的笔迹,正确理解问题的表述,将问题和解决方案都转换为数学公式,识别出学生在解决问题时出错的具体推理步骤,然后给出问题的正确解决方案。
高级编码
Gemini 可以理解、解释和生成流行编程语言(如 Python、Java、C++、Go)的高质量代码,具备强大的跨语言工作和推理复杂信息的能力使其成为世界领先的编码基础模型之一。
Gemini Ultra 在多个编码基准测试中表现出色,包括 HumanEval(用于评估编码任务性能的重要行业标准)和 Natural2Code(谷歌内部数据集),该数据集使用作者生成的源代码而不是基于网络的信息。
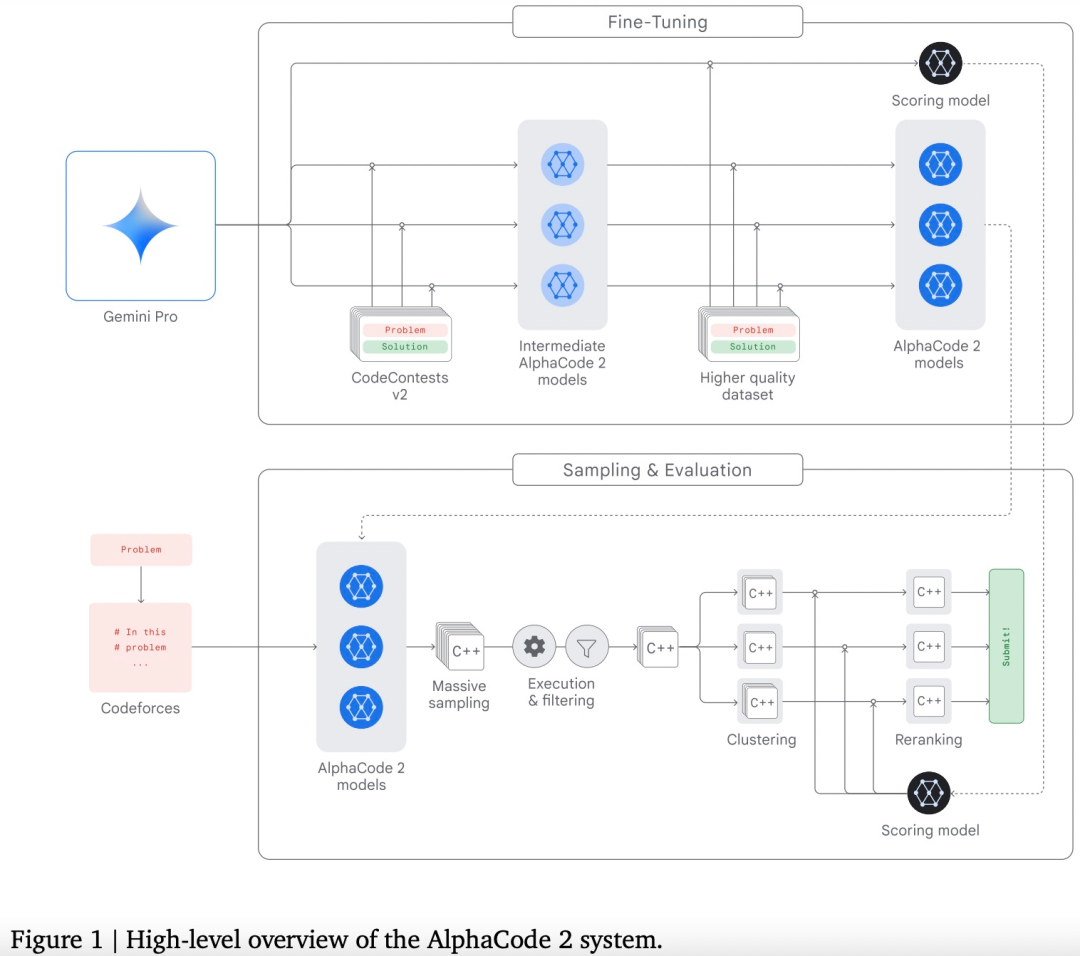
Gemini 还可以用作更高级编码系统的引擎。两年前,谷歌推出了 AlphaCode,这是第一个在编程竞赛中达到竞争性水平的人工智能代码生成系统。
使用 Gemini 的专门版本,谷歌创建了更先进的代码生成系统 AlphaCode 2,它擅长解决超出编码范围、涉及复杂数学和理论计算机科学的竞争性编程问题。
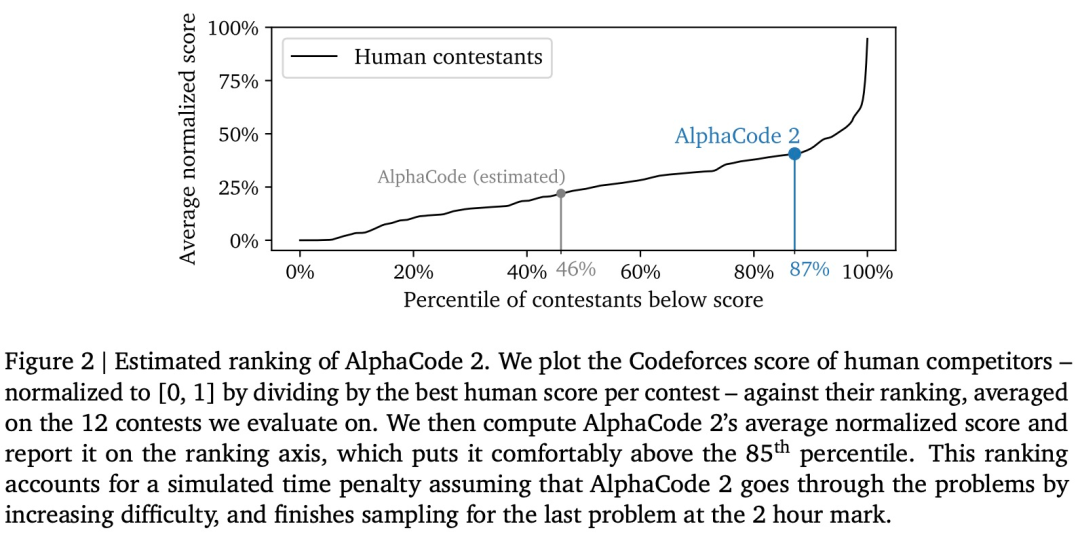
经过与原始 AlphaCode 在相同平台上进行评估,AlphaCode 2 展现出巨大的改进,解决的问题数量几乎是原来的两倍。
专用 TPU 训练
谷歌使用内部设计的张量处理单元 (TPU) v4 和 v5e 在人工智能优化基础设施上对 Gemini 1.0 进行了大规模训练,并将其设计为最可靠、可扩展的训练模型和最高效的服务模型。
在 TPU 上,Gemini 的运行速度明显快于早期规模较小、能力较弱的模型。这些定制设计的 AI 加速器是谷歌人工智能产品的核心,这些产品为搜索、YouTube、Gmail、谷歌地图、Google Play 和 Android 等数十亿用户提供服务。它们还帮助世界各地的公司经济高效地训练大规模人工智能模型。
今天,谷歌同时发布了迄今为止最强大、最高效、可扩展的 TPU 系统 —Cloud TPU v5p,专为训练尖端的人工智能模型而设计。新一代 TPU 将加速 Gemini 的发展,帮助开发人员和企业客户更快地训练大规模生成式 AI 模型,让新产品和新功能更快地与客户见面。

Google 数据中心内的一排 Cloud TPU v5p AI 加速器超级计算机。
谷歌旗下产品将全线升级
从今天开始,谷歌将在其产品中添加 Gemini,例如 Bard 将使用 Gemini Pro 的微调版本来执行更高级的推理、规划、理解等任务。这也是 Bard 自推出以来最大的升级。
升级版 Bard 将在 170 多个国家 / 地区提供英语版本,并且在不久的将来会扩展到更多模态,并支持更多种语言。
谷歌还将 Gemini 引入了 Pixel。Pixel 8 Pro 将是第一款运行 Gemini Nano 的智能手机。

Pixel 8 Pro 在录音机应用中使用 Gemini Nano 来总结会议音频,即使没有网络连接也可以实现。
在接下来的几个月中,Gemini 将陆续出现在谷歌更多的产品和服务中,包括搜索、广告、Chrome、Duet AI 等等。
谷歌表示其已经在搜索中试验了 Gemini,它使用户的搜索生成体验 (SGE) 速度更快,延迟减少了 40%,同时质量也得到了提升。
使用指南及未来规划
最后,开发者如何使用 Gemini?
从 12 月 13 日开始,开发人员和企业客户可以通过 Google AI Studio 或 Google Cloud Vertex AI 中的 Gemini API 访问 Gemini Pro。
从 Pixel 8 Pro 设备开始,Android 开发人员还可以通过 AICore 使用 Gemini Nano 进行构建。Android AICore 是 Android 14 中的一项新系统服务,可处理模型管理、运行时、安全功能等,简化用户将 AI 融入应用程序的工作。
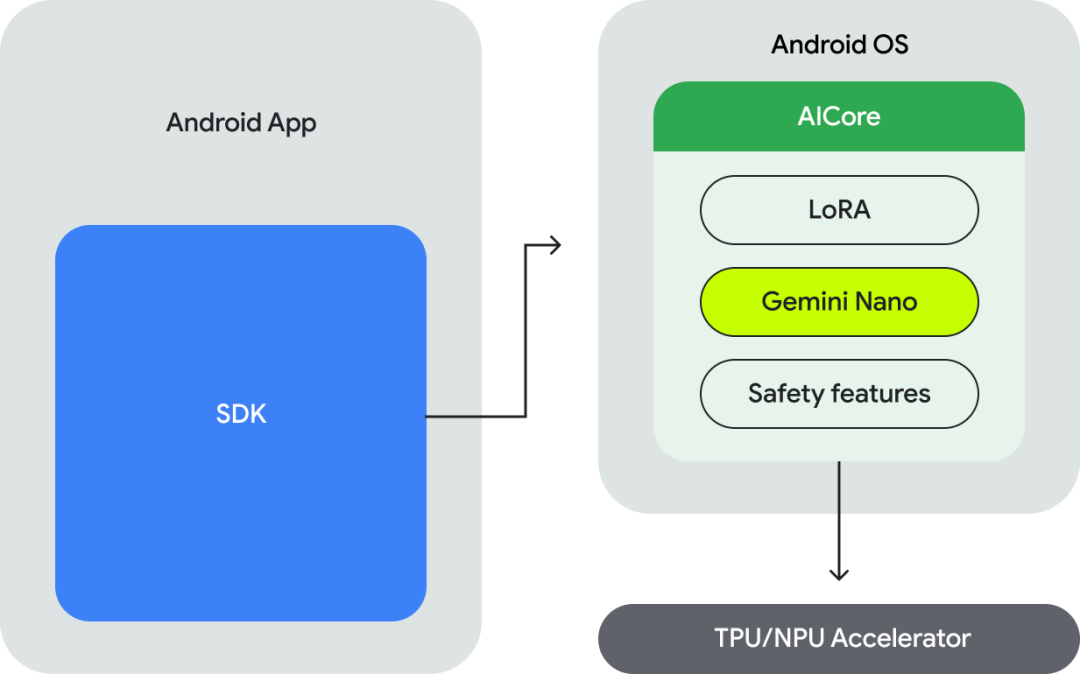
AICore 通过 Gemini Nano 实现低秩适应 (LoRA) 微调。这个强大的概念使应用程序的开发人员能够根据自己的训练数据创建小型 LoRA 适配器。LoRA 适配器由 AICore 加载,从而产生针对应用程序自身用例进行微调的大型语言模型。
另外,谷歌剧透了 Gemini Ultra 将会在不久后发布,以及 Bard 的下一步升级计划。
Gemini Ultra 模型目前正处于信任和安全检查阶段,包括由可信赖的外部各方组成的红队(red team),并使用微调和人类反馈强化学习(RLHF)进一步完善模型。
在这个过程中,谷歌会先向部分客户、开发人员、合作伙伴以及安全和责任专家提供 Gemini Ultra,供其进行早期实验和反馈,然后在明年初向开发人员和企业客户推出。
Gemini Ultra 是谷歌最大、功能最强大的模型,专为高度复杂的任务而设计。普通用户体验 Gemini Ultra 的首个方式会是通过 Bard Advanced,谷歌将在明年年初推出 Bard Advanced。
谷歌表示,未来将努力扩展 Gemini 的功能,包括在规划和记忆方面的进步,以及增加上下文窗口以处理更多信息,从而做出更好的响应。
博客链接:https://blog.google/technology/ai/google-gemini-ai/#scalable-efficient